
Regression testing
TextChart Studio has a built-in regression testing feature for measuring the impact that changes to the LxBase have on the output. When a corpus is active, all saved regression points are listed in a chart below the corpus entry in the Corpus Management page.
To create a new regression point, click Create New Regression Point 
in the horizontal toolbar above the corpus entry.
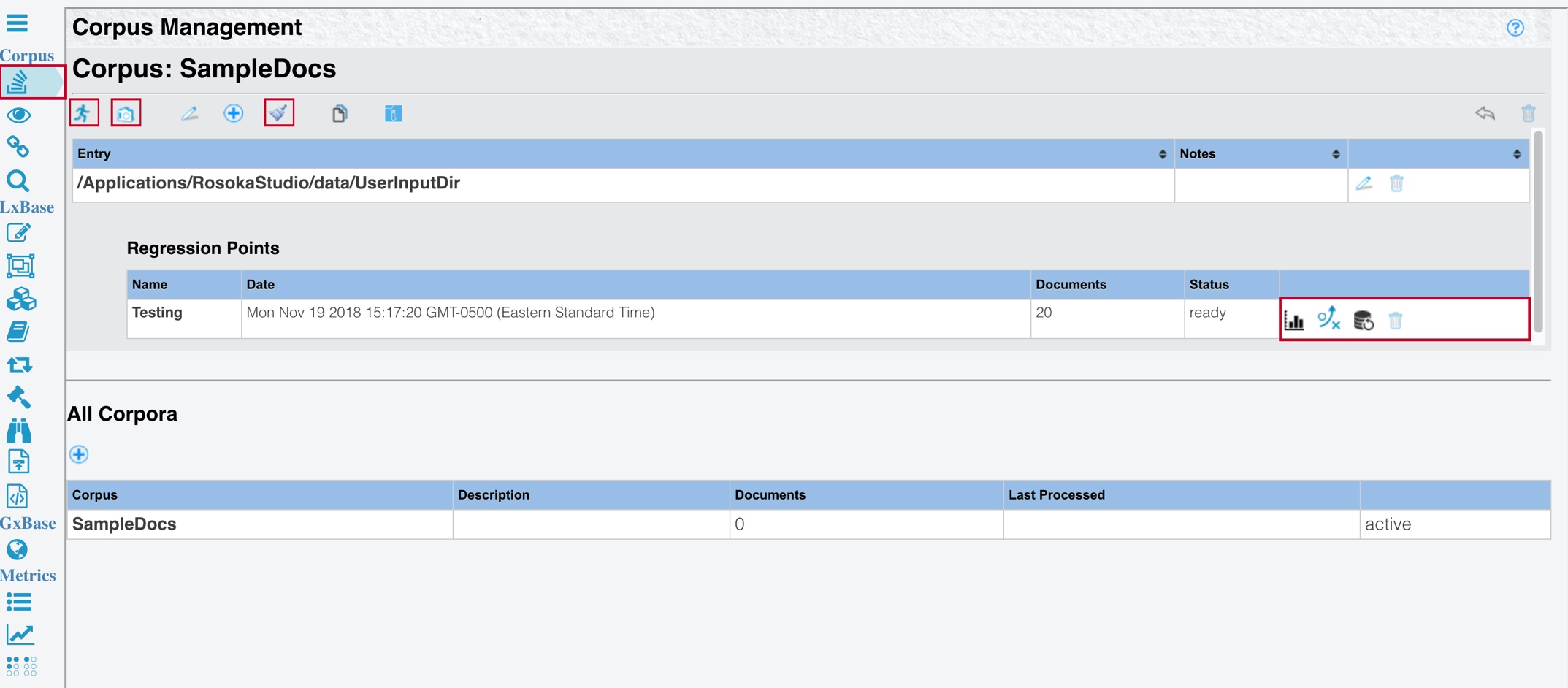
After you make lexical or rule modifications to the LxBase, you can score a current run against a regression point. First, click Clear Processing Results to remove any previous results from the comparison. Then you need to reprocess the corpus.
To compare the results of the current run with a regression point, click Score against current results 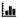
in the appropriate row of the corpus list, or Compare and score results in the Metrics section of the vertical toolbar. You can save multiple regression points and test against any of them.
TextChart Studio retains regression points and scoring results until you delete them. To view scoring results without prompting a new run, click View Score Results in the appropriate row. You can also revert the active LxBase to an earlier version by clicking Restore saved LxBase.
Interpreting results
As you view the scoring results of a regression run, you can click the table at the top of the Scoring page to see a breakdown for each entity type.
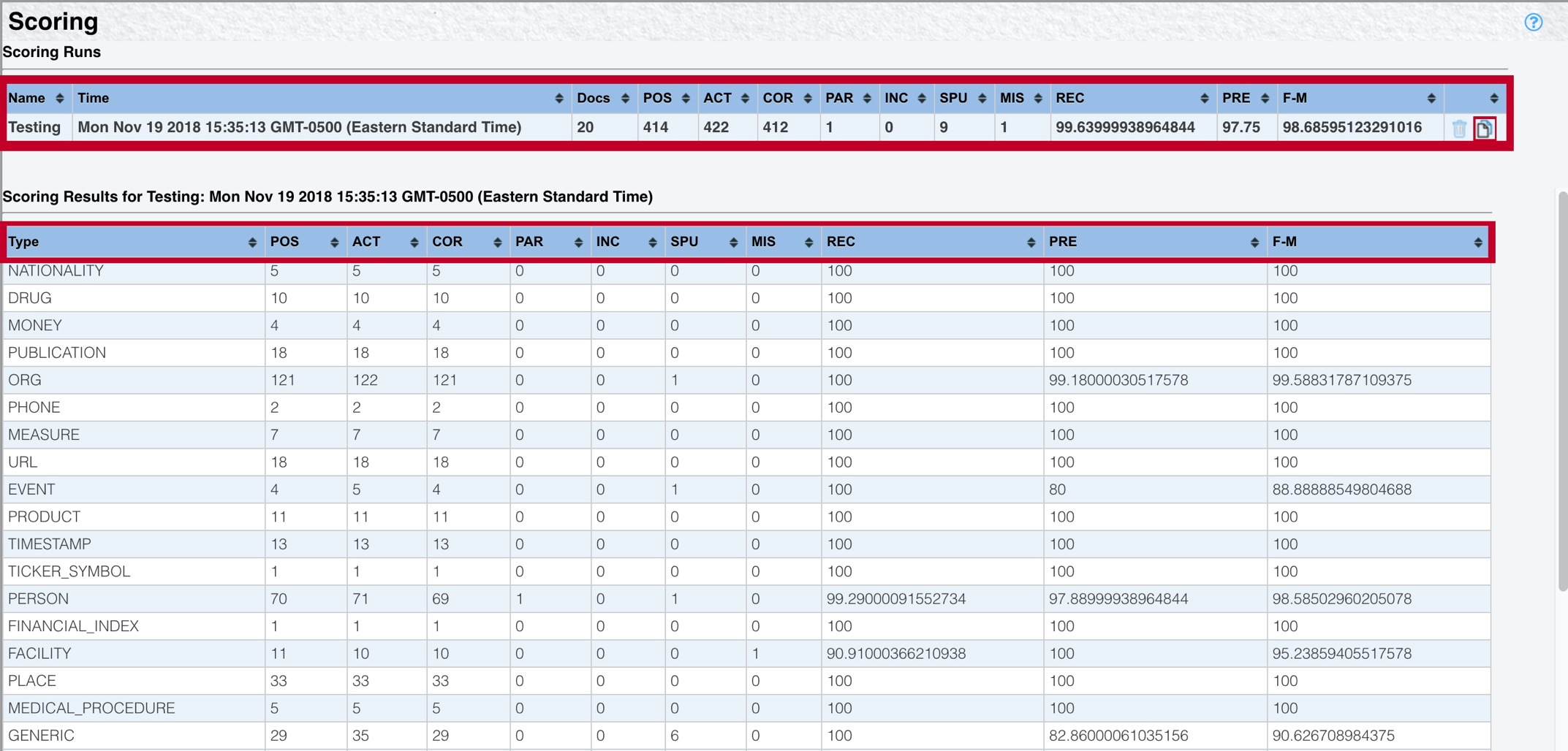
The scoring run produces the following results:
POS (possible) - The number of possible entities (based on key)
ACT (actual) - The number of entities extracted during the current run.
COR (correct) - The number of correct entities (matching the key)
PAR (partial) - The number of partial entities, where a portion of the string overlaps with an entity from the key.
INC (incorrect) - The number of incorrect entities, where the string overlaps exactly with an entity in the key, but the entity type is different in the current run.
SPU (spurious) - The number of new entities not in the key.
MIS (missing) - The number of missing entities, where the entity is in the key, but not in the current run.
REC (recall) - The proportion of actual entities (from the key) that are extracted as entities (in the current run).
PRE (precision) - The proportion of postulated entities (from the current run) that are actual entities (from the key).
F-M (F-measure) - A weighted average of precision and recall, between 0 and 1, with 1 being a perfect score. The formula uses β = 1, meaning that precision and recall are weighted equally.
As an alternative to the breakdown table, you can click View Detailed Score Results in Documents in the top table to view a list of the documents that have extraction differences.
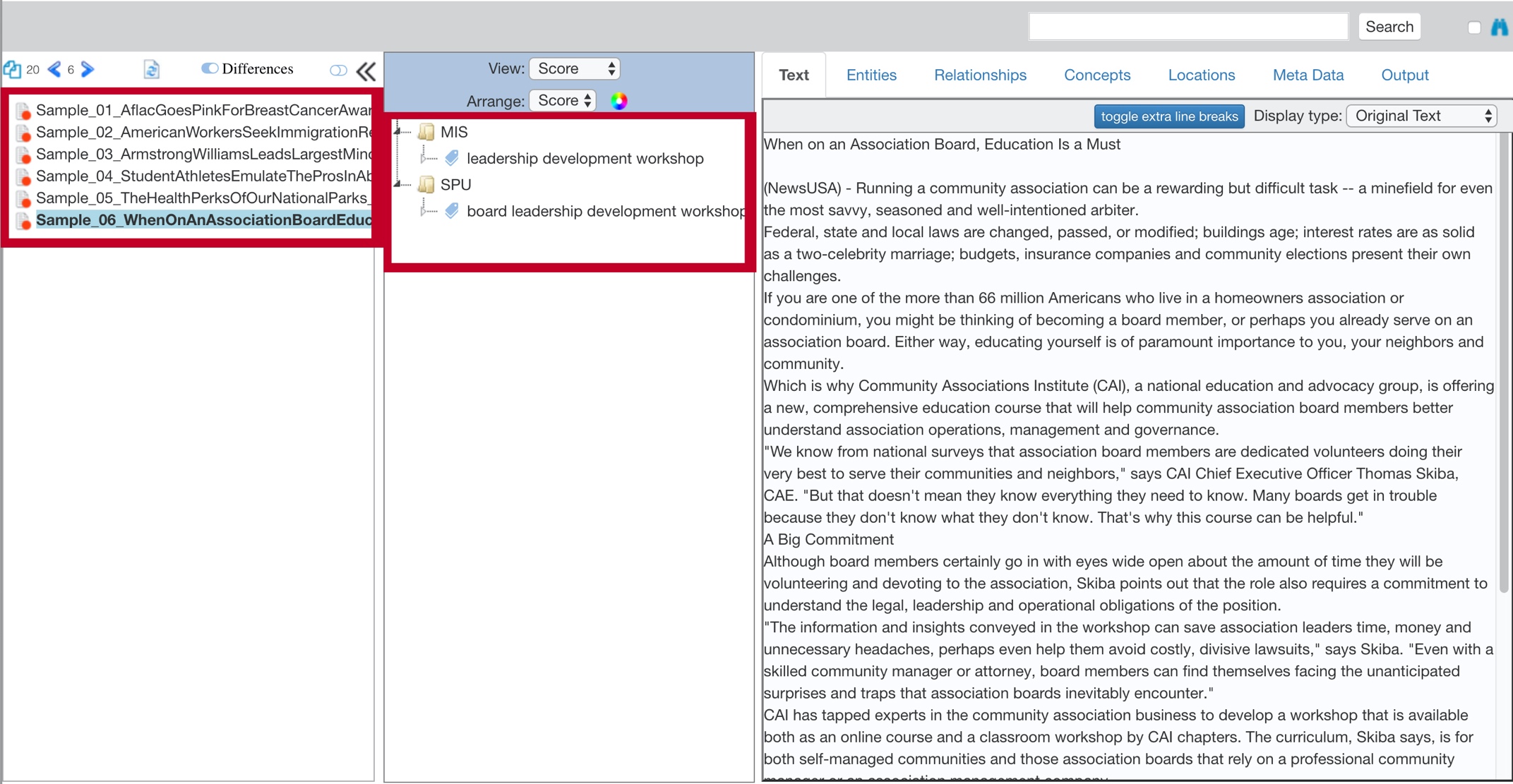
If there are no differences, the view is empty. However, a document with a red dot next to its name means that TextChart Studio has detected an extraction change.
Click each document to review the extraction changes. Click the Differences button above the list of documents to move between the original extraction results and the new ones. This view displays scoring changes in the center column.