
Corpus management
When you first log in to i2 TextChart Studio, you're prompted to create an initial corpus of documents that you'll use to evaluate the changes you make to the LxBase. optionally, you can create multiple, named corpora with different sets of documents.
The Corpus Management page in TextChart Studio allows you to add, remove, and process corpora; to toggle between different saved corpora; and to perform a variety of other document management functions.
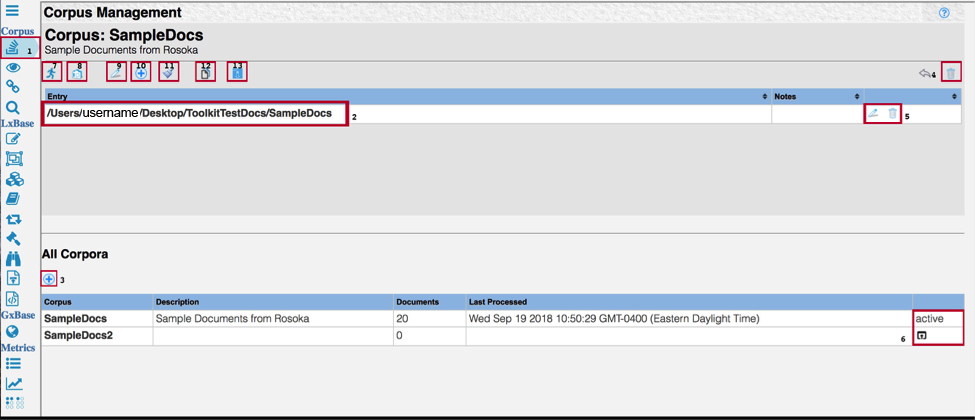
To open the the Corpus Management page, click the View Corpus List icon located towards the top of toolbar.
The list at the top of the page indicates the active corpus. Corpus management commands act only on the active corpus.
To return to the Create New Corpus page, click the Add a New Corpus button above the All Corpora list at the bottom of the page.
To remove the active corpus from the Corpus Management page, click Delete Corpus.
To edit the path of the active corpus, use the Edit Entry and Delete Entry buttons.
To make a different corpus active, click the Open Corpus button on the right of the All Corpora list.
To make TextChart Studio process all the documents in the active corpus, click Process all Documents in the horizontal toolbar.
To take a snapshot of the LxBase in its current form for later comparisons, click Create New Regression Point.
You can use TextChart Studio's regression testing feature to measure the impact that your changes to the LxBase have on the output. For more information, see Regression Testing.
To change the name or the description of the active corpus, click Edit Corpus Name/Description.
To add more documents to the active corpus, click Add More Files.
If you modify any dictionaries or linguistic rules after you process the active corpus, you must clear the previous results before you reprocess the corpus. To do so, click Clear Processing Results.
TextChart Studio automatically removes duplicate documents upon processing. Click Show Duplicate Documents to see a list of these duplicates. Raw documents are documents that are the same before Tika processing; content duplicates are documents that are the same after Tika processing.
Sometimes, TextChart finds words that it does not understand. Typically, these words belong to subject-specific vocabularies, or they pertain to proprietary industry information, or they are non-English words for which TextChart has no translation.
To download a list of these words, potentially to add them to a custom LxBase, click Download Unknown Words

above the entry information line.Select which language to download an unknown word list for, and then click Submit to compile the list, which can take several minutes. When you see a notification, click the icon to download the list as a ZIP file.