i2 TextChart
Welcome to the i2 TextChart documentation, where you can find information about how to use and administer i2 TextChart.
i2 TextChart is designed to let you seamlessly process and analyze unstructured documents in over 200 languages in Analyst's Notebook. Over three dozen important entity types, including people, organizations, and locations, as well as their relationships or links can be extracted.
After the automated process, you can modify extracted entities, tag a new entity or link, delete a system-tagged entity, or accept the entities that have been identified by TextChart. The combination of the automated text analysis and human input allows you to efficiently analyze the growing collections of unstructured documents and collaborate across your organization.
You can leverage all of the powerful visualization and analytical features of Analyst's Notebook to build charts from entities and expand the network of entities and links that were identified in documents that have been previously processed. In addition to helping you understand how entities are related, the application lets you view all documents that contain entities and links of interest.
Configuration
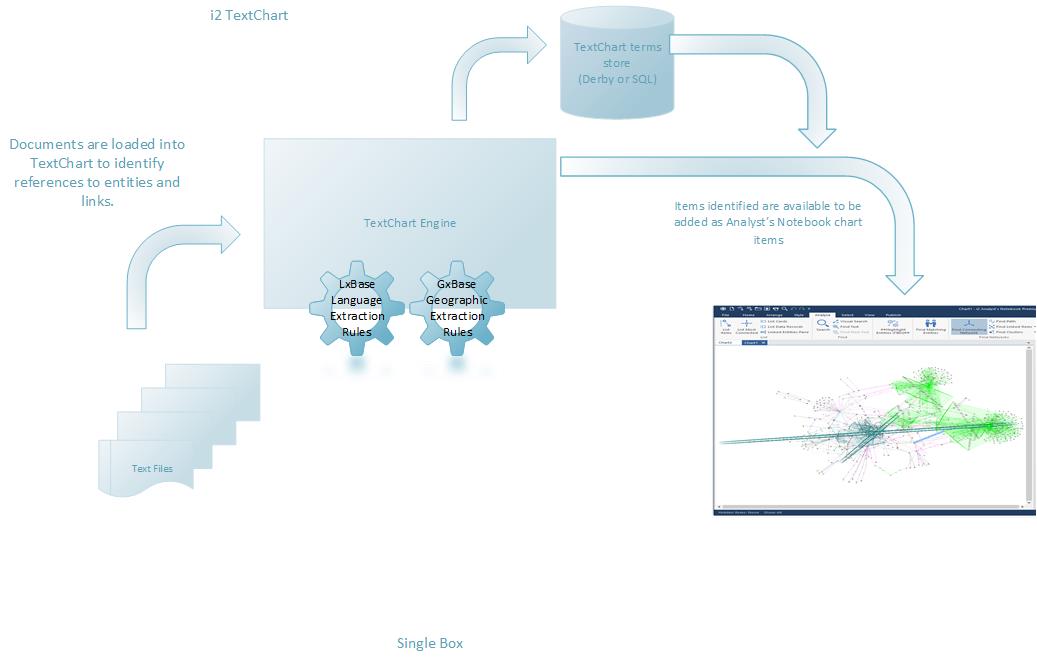
TextChart is shipped as an out-of-the-box offering, it includes standard term extraction rules and, with the embedded term storage option, requires very little configuration.
If needed, however, you can modify the term extraction rules and then merge your custom terms with later standard term updates as they are released. In addition, you can add a terms database that allows you to store extracted terms for later use.
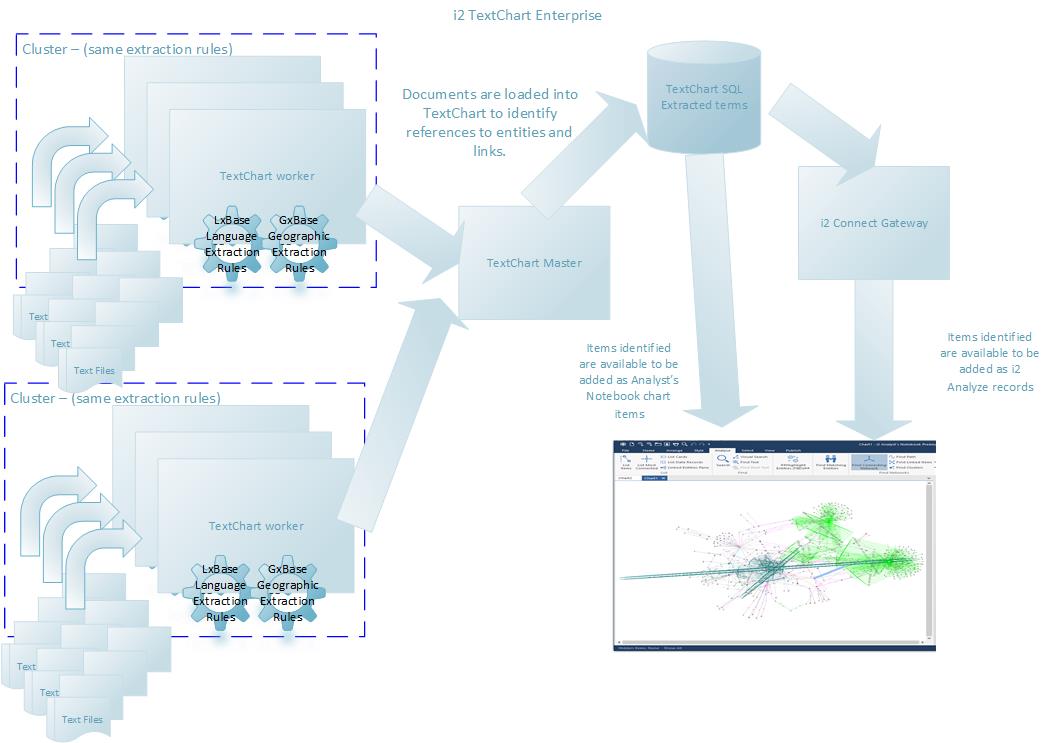
Upgrading to TextChart Premium increases the scale of your deployment significantly:
Documents from different sources can be extracted using different extraction rules.
Terms can be loaded in bulk from multiple sources.
Terms are stored in a database that allows i2 Connect to be used to create i2 Analyze records in addition to standard Analyst's Notebook chart items.
Key components
There are a number of key moving parts in every TextChart deployment:
File locations: the file system paths that contain documents to be processed
Extraction engine: where documents are processed to extract the terms that they contain
LxBase: the lexicon definition, which is the list of rules that determine how terms are identified in the source material
GxBase: the geographic definition, which is the list of rules that determine how geographic locations are identified in the source material
In addition, in a standard TextChart deployment you might also wish to set up a repository for the extracted terms, and external mapping applications to work with geographic data.
A TextChart Premium deployment can be scaled to match your needs, allowing different file types to be extracted using different rules, automated updates as files change or new documents become available, and integration with the i2 Connect gateway to create i2 Analyze records for your chart items: