
Viewing corpus results
By default, the Active Corpus page contains information about a single document in that corpus. Here, you can view a single document with hit highlights, select certain entities to view, explore the lexical items, and view rule traces.
To open the Active Corpus page, click the View Active Corpus icon near the top of the vertical toolbar.
To see a summary of the extraction results for the whole corpus, click Aggregate View.
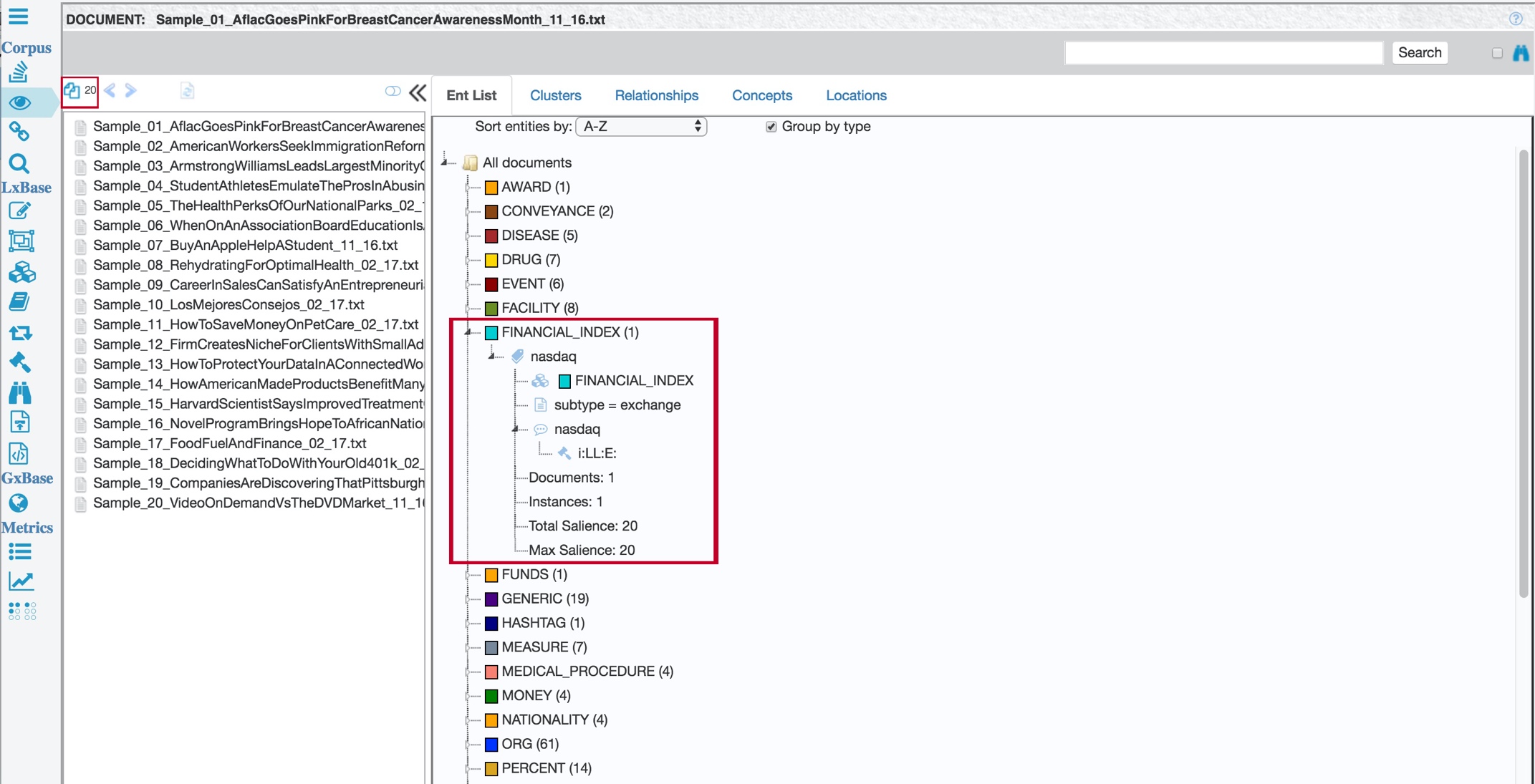
Each entity type that TextChart Studio found in the corpus is listed, along with its total number of extraction instances. You can open entries in the list to see individual extraction results and their corresponding metadata.
To view the results for each document in the corpus, click the Next Document and Previous Document buttons. TextChart Studio displays the text for the document on the right of the page, with highlights corresponding to the extracted entities.
When you make changes to the LxBase, and you want to see the effect of those changes on a single document without reprocessing the whole corpus, click Reprocess the Current Document.
Instead of navigating through the documents in the corpus, click Switch to Search Mode to view the results for a specific document by name.
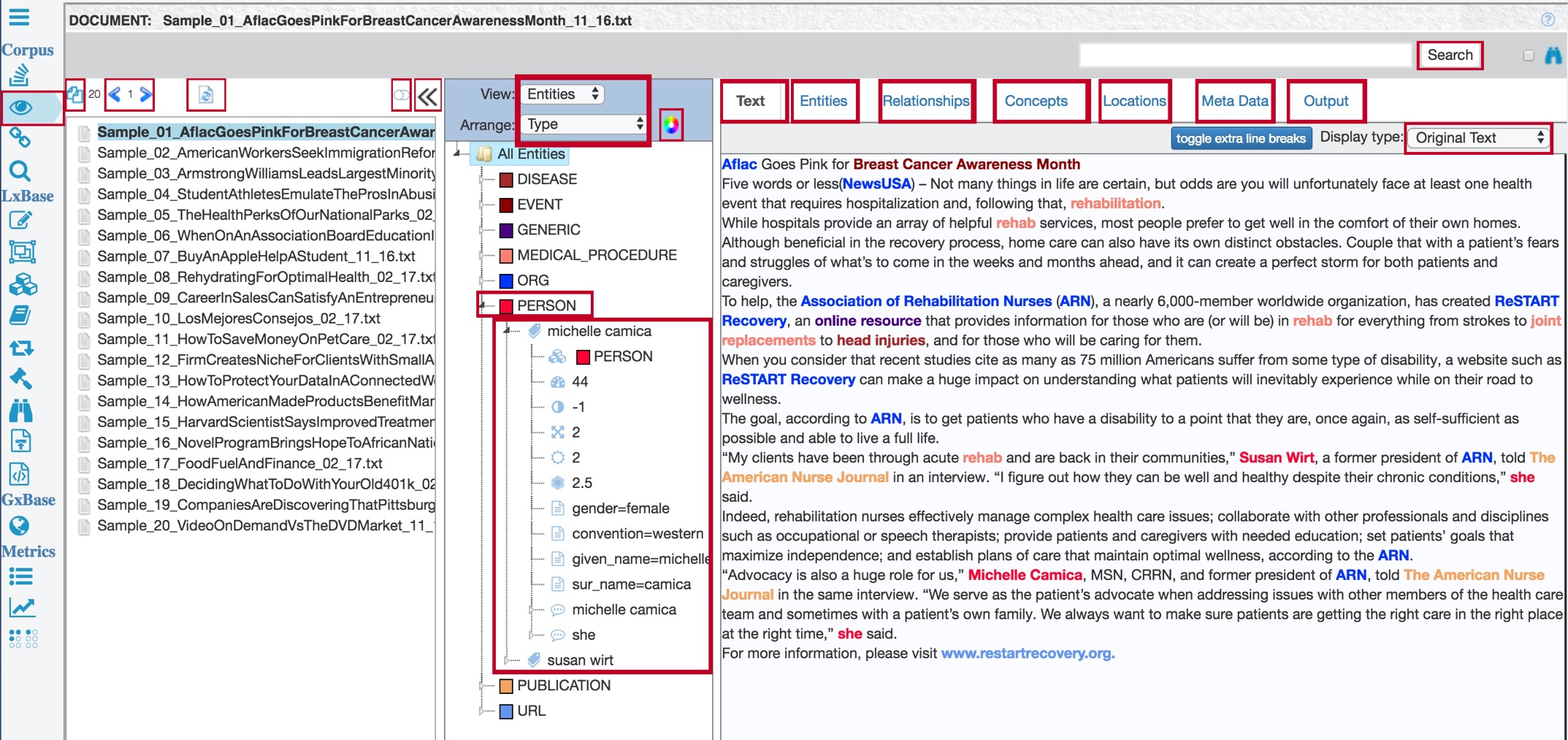
When you select a single document in the corpus, the tree view in the center of the Active Corpus page displays the extraction results for that document. Use the View and Arrange lists to change how the results are represented.
On the right of the Active Corpus page, the Text tab contains the text of the selected document with hit highlights corresponding to the extracted entities.
The Entities tab contains a visualization of extracted entities and their overall importance within the selected document.
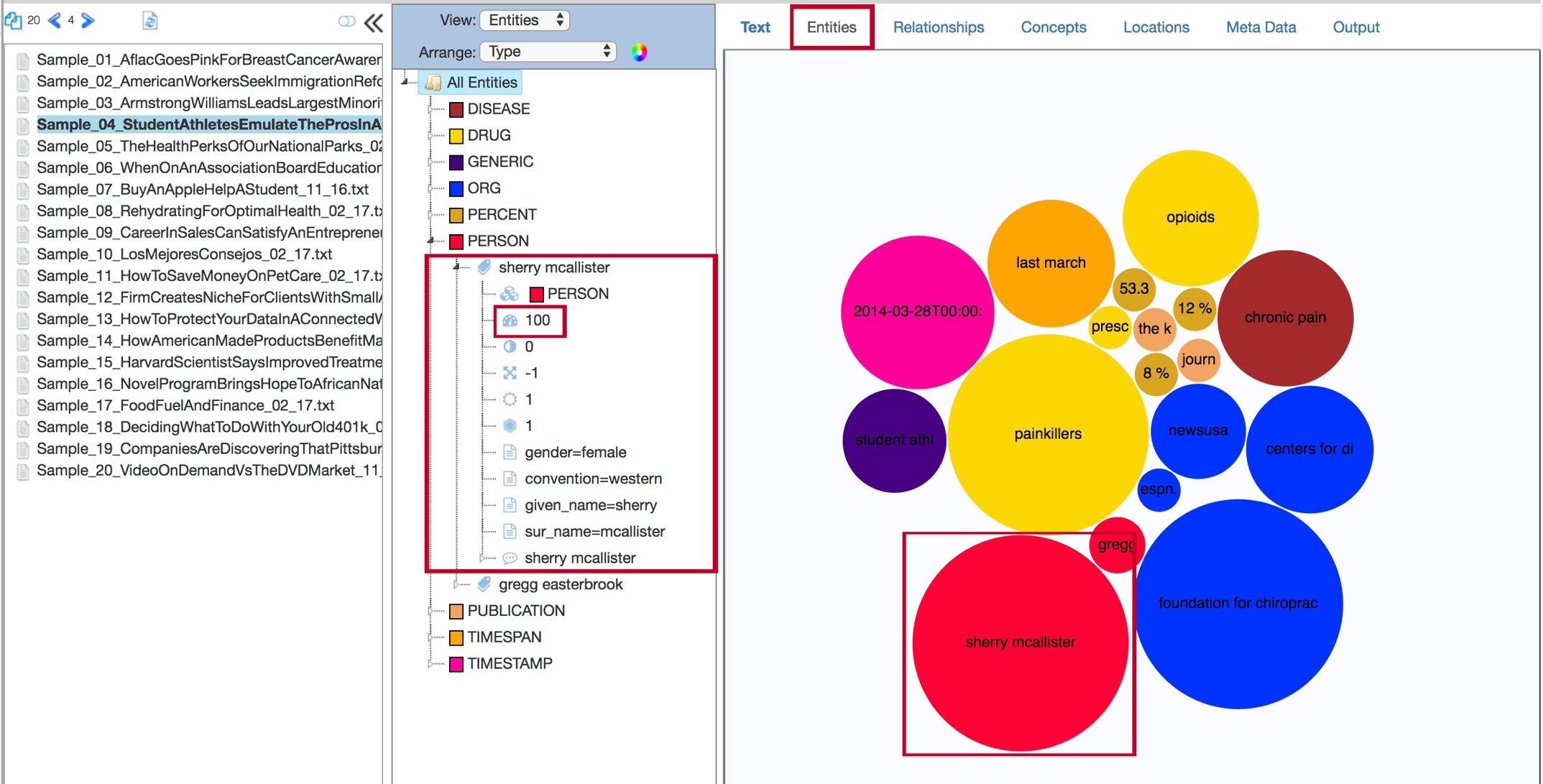
The larger the circle that represents the entity, the more important (or salient) that entity is to the document. Salience is scored from 0 to 100, with 100 representing the most entity.
The Entities tab is also available in the aggregate view, where its contents represent the salience of extracted entities to to the corpus as a whole.
The Relationships tab contains a visualization of extracted entities and their relationships to each other in the selected document.
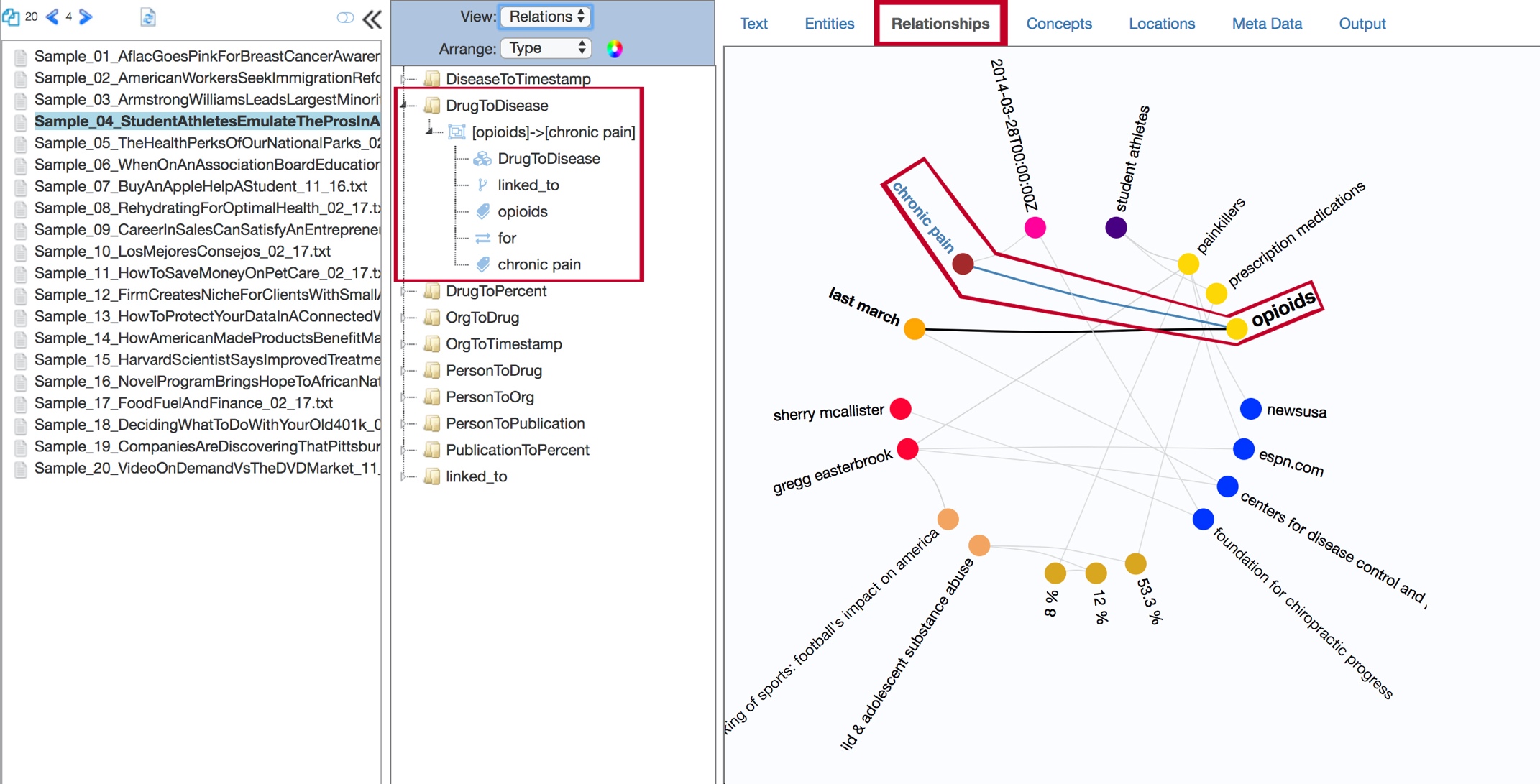
You can interact with the contents of the Relationships tab to gain information about the subjects, objects, and predicates that prompted each extracted relationship.
The tab is also available in the aggregate view, where its contents represent relationships between entities across the whole corpus.
The Concepts tab contains a visualization of extracted entities, as well as other words or phrases that TextChart has identified as salient by their overall importance to the selected document.
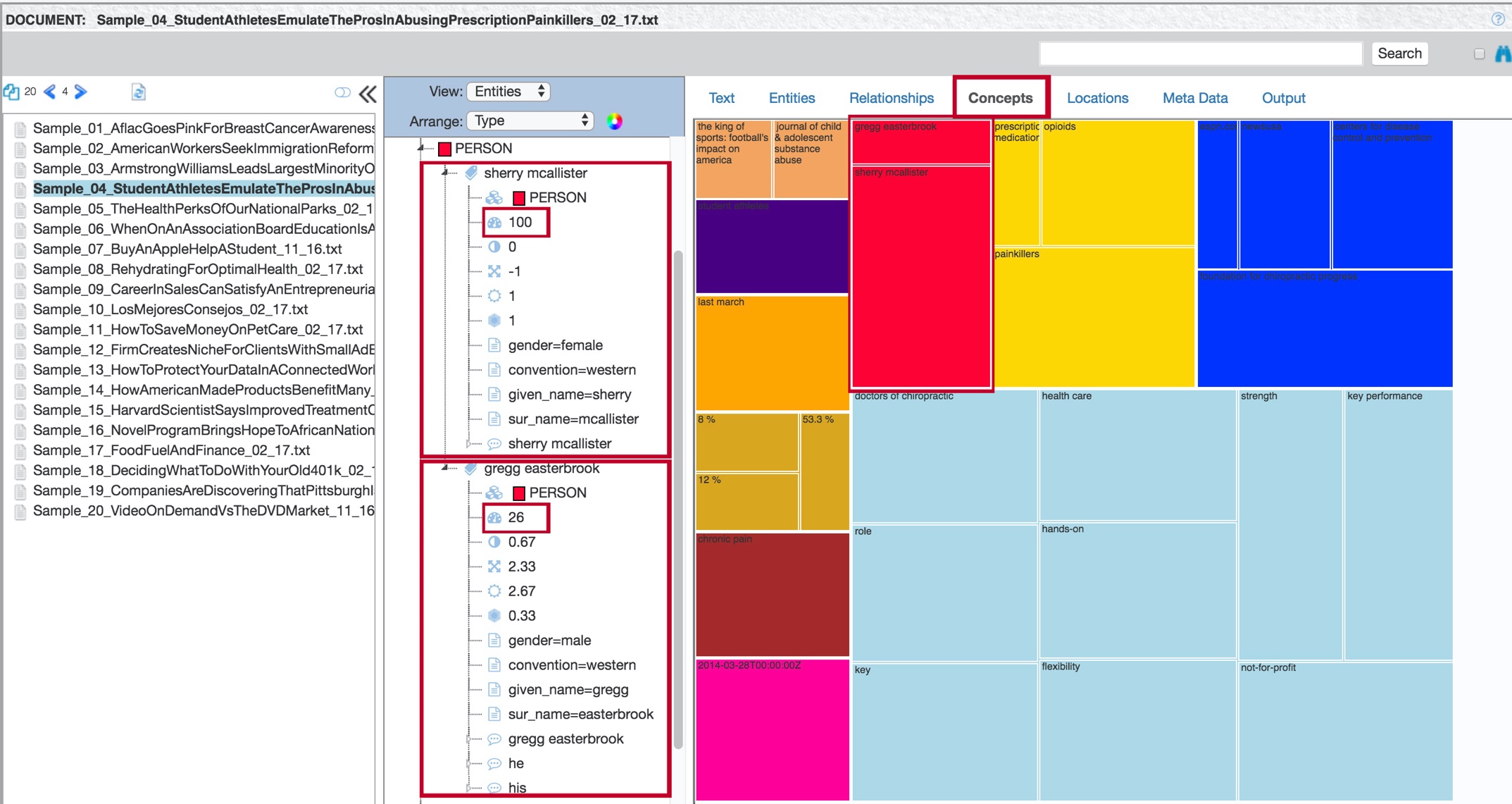
The larger the box that represents the entity, the more important (or salient) that entity is to the document.
The brightly colored boxes represent individually extracted entities, while the light blue boxes represent salient words or phrases. You can use this information to see if there are any additional items that need to be modified to reach your extraction goals.
The Concepts tab is also available in the aggregate view, where its contents represent the salience of words and phrases to the corpus as a whole.
The Locations tab contains a visualization of extracted entities and their geographic locations from the selected document.
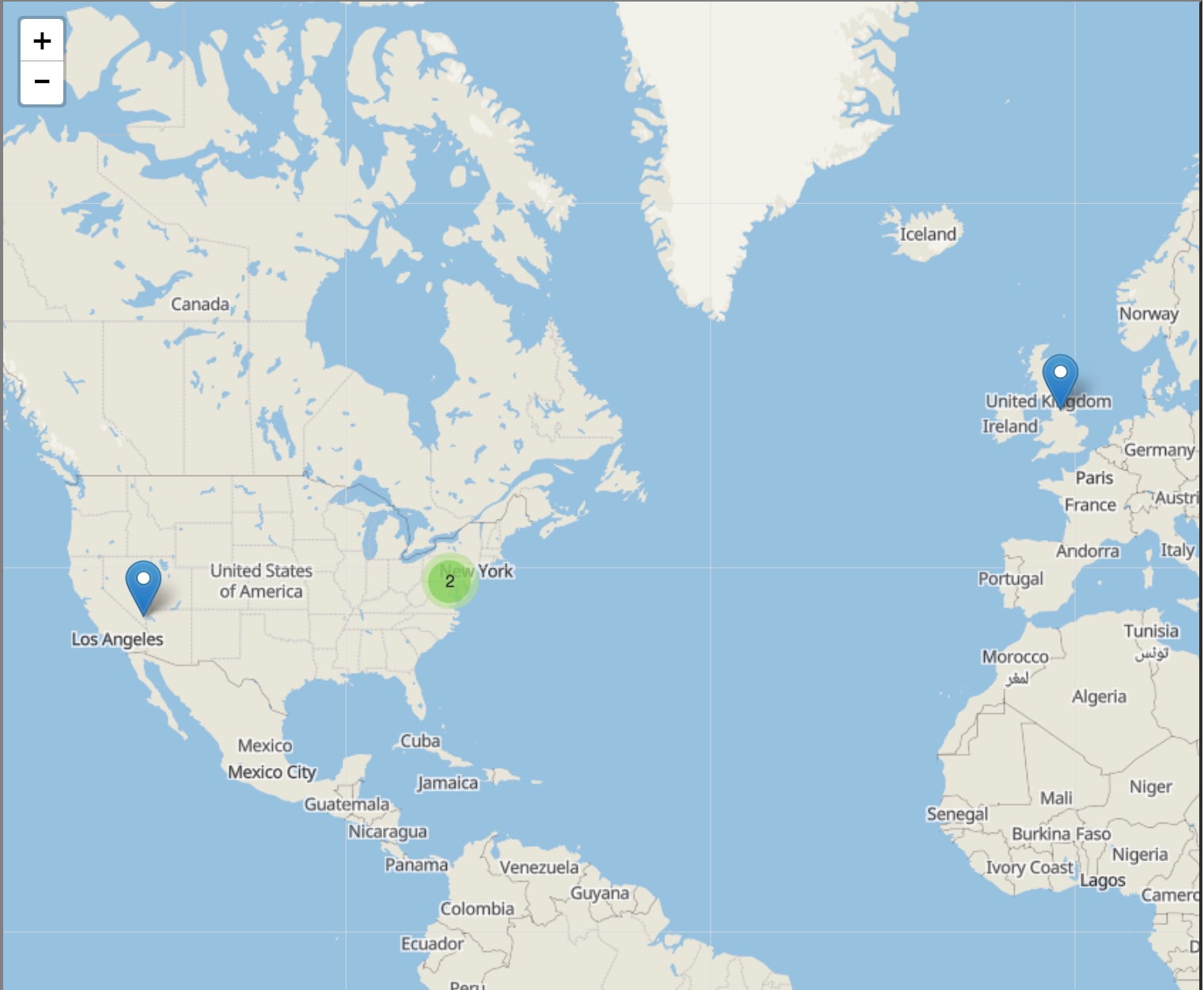
This tab is also available in the aggregate view, where its contents represent the locations of entities from across the corpus as a whole.
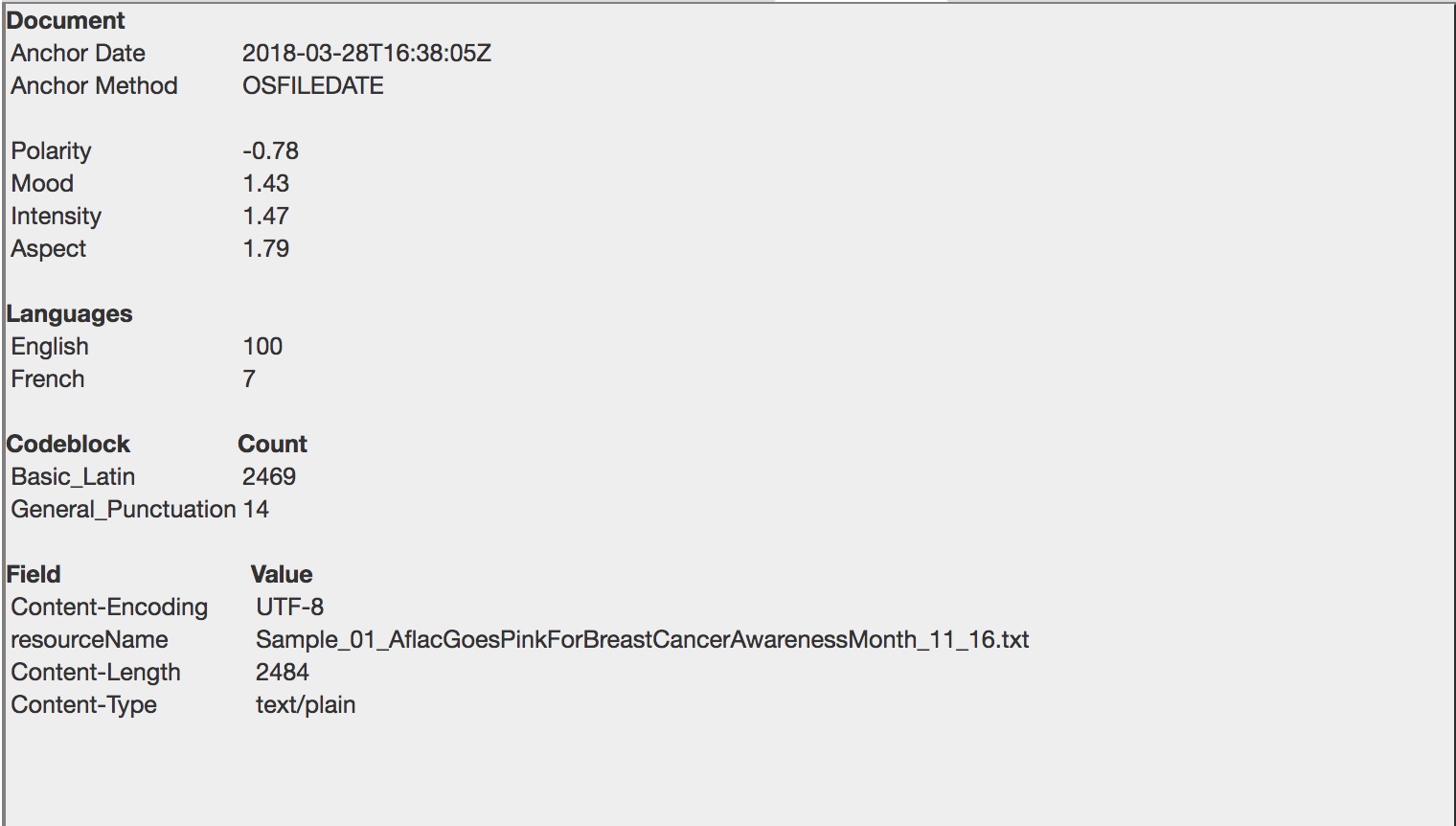
The Metadata tab presents the user with document-level metadata, including overall sentiment scores and the languages identified in the selected document.
The Output tab contains the raw output generated from the extraction process for the selected document, in JSON or XML format.
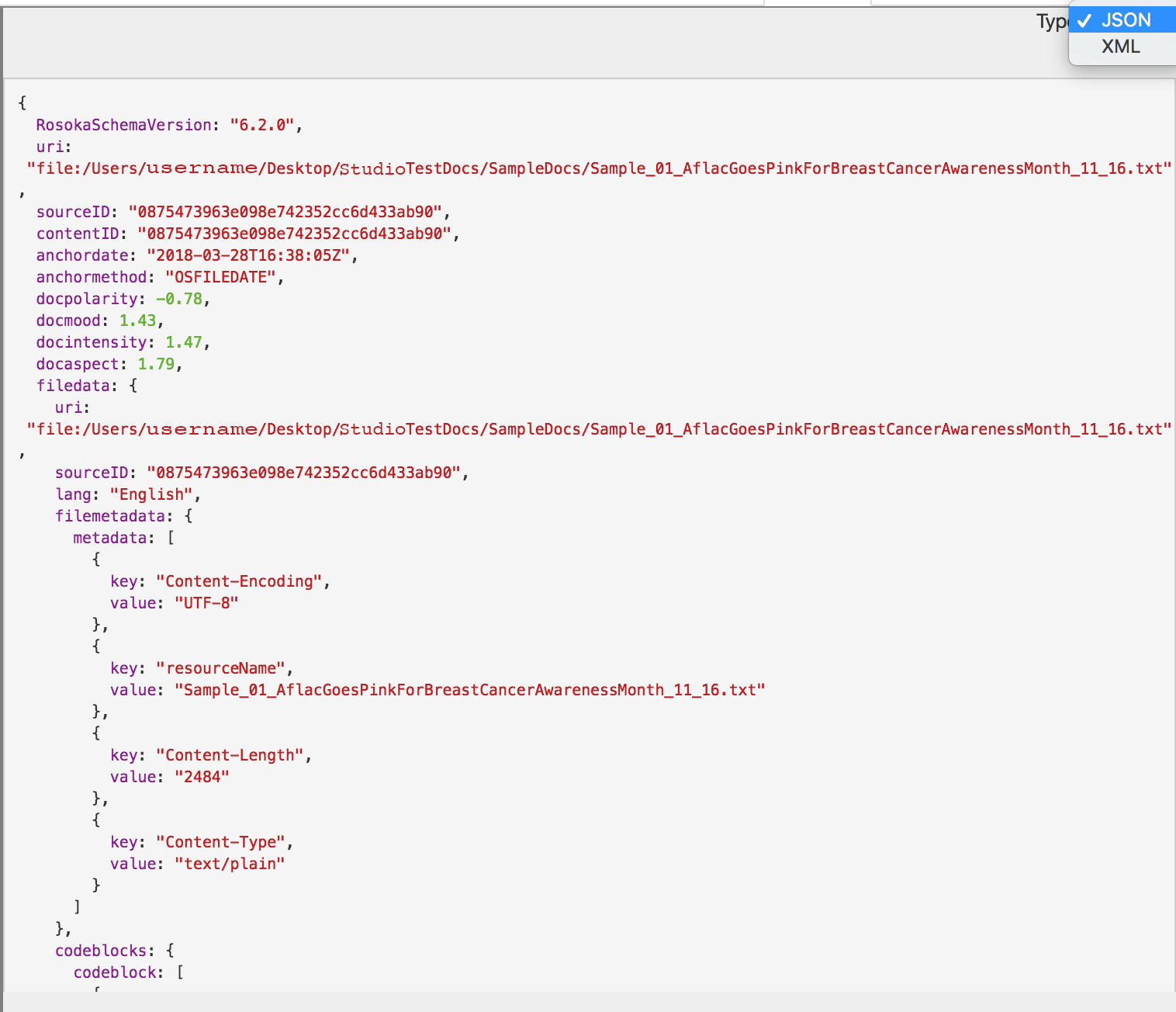
This information is what would be sent to the database if the current LxBase had processed the document in a production environment. You can view the output in its source language or with an English gloss, and get a breakdown of the individual tokens, entities, sentiment scores, and relationship extraction results.
Use the Search function to find all the documents in the corpus that contain a particular word or phrase, effectively filtering the document list.
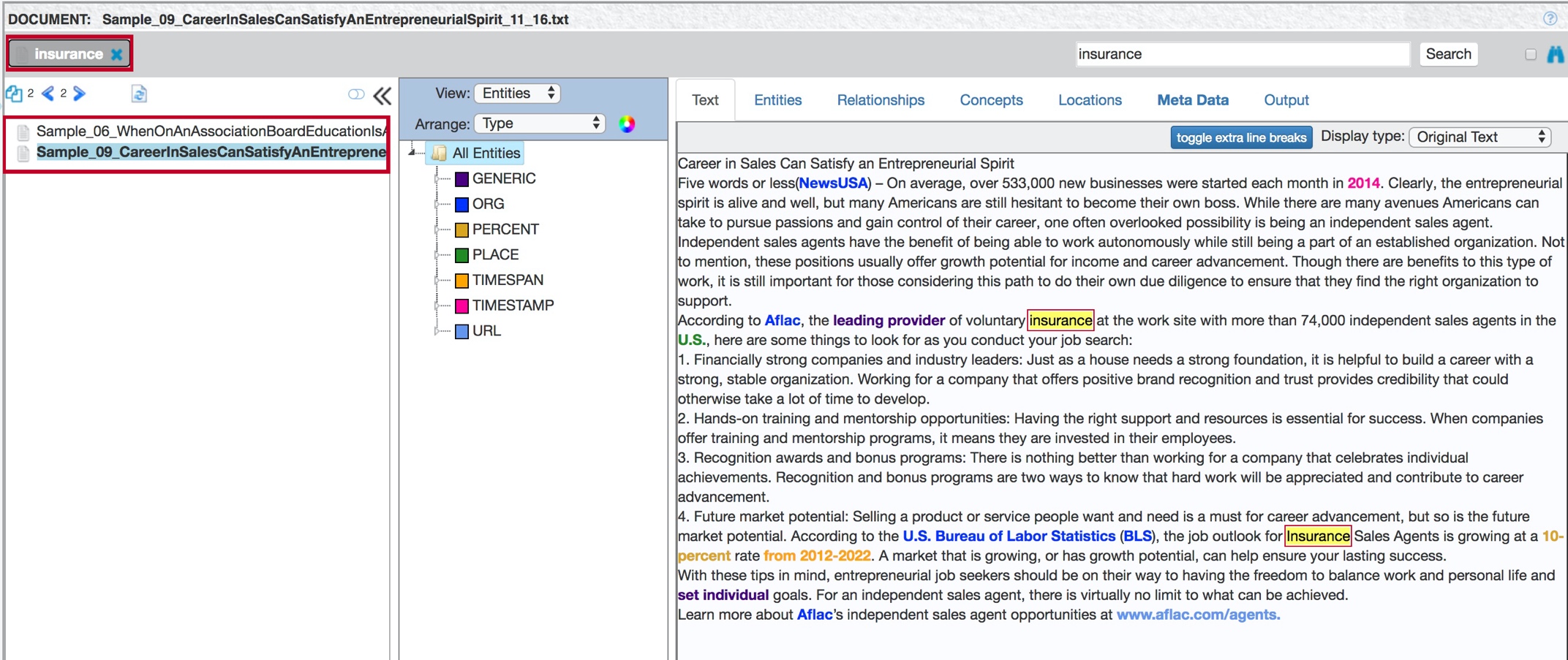
When you select a document from search results, the contents of the Text tab highlight not only extracted entities but also the terms that you searched for.
When you're viewing a single document, you can use the Display type options to view the original text in its source language, with an English gloss, or both.
In the side-by-side view, hovering over an element on either side highlights the corresponding information in both views.