
Exploring processed text
TextChart Studio's Text tab allows you to modify the current LxBase directly, by interacting with the highlighted extraction results. Right-click any result to see a pop-up menu with a list of the available options.
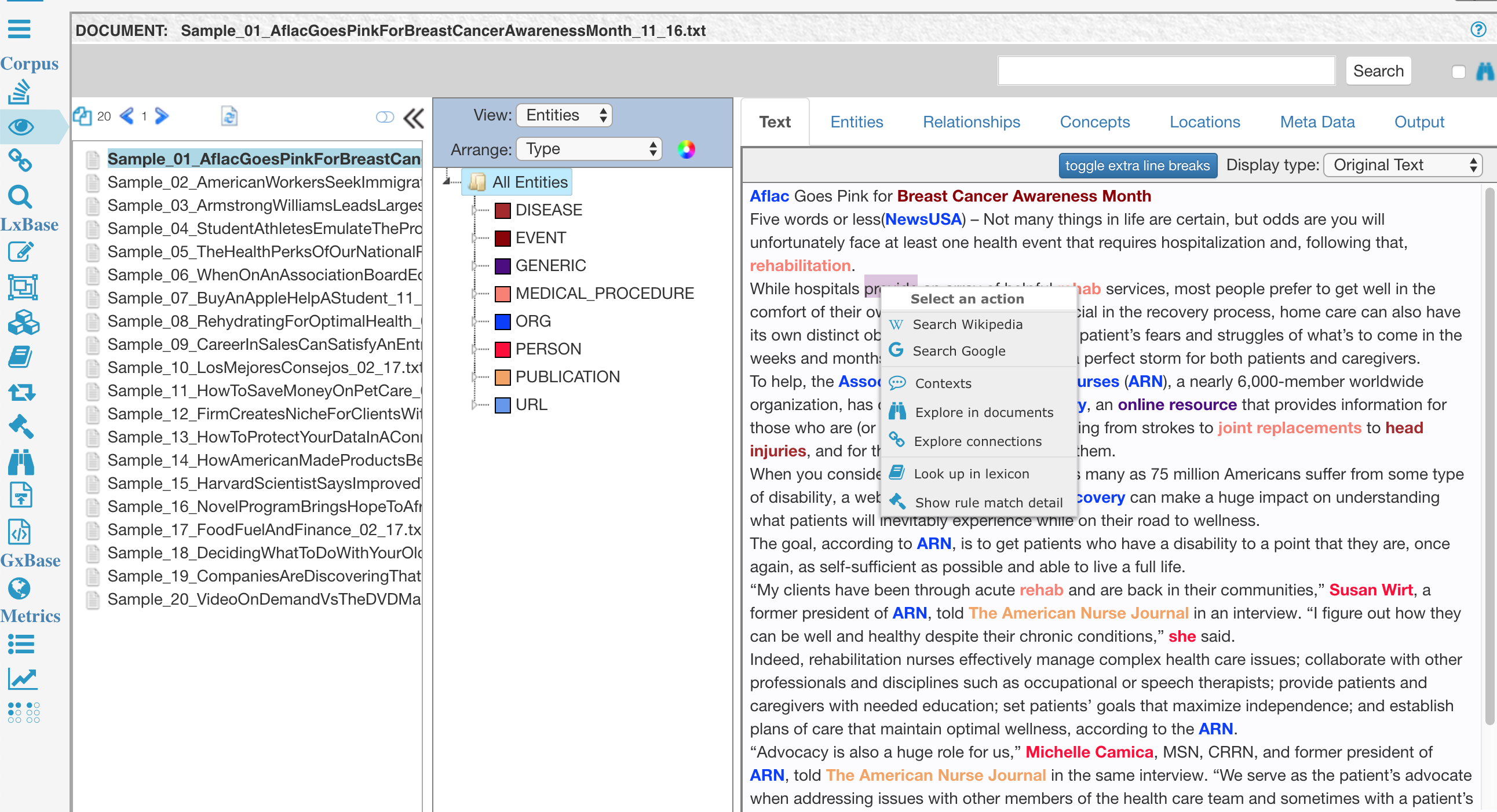
Among other things, the menu enables you to search for the result in both Wikipedia and Google. You can also open different views in TextChart Studio, as well as modify the associated semantic vectors.
Document search
Select Document search from the pop-up menu to perform a fuzzy search for the extraction result across all documents in the corpus. The results are a list of the documents that matched the search, along with a brief sample of the context in which the result was found.
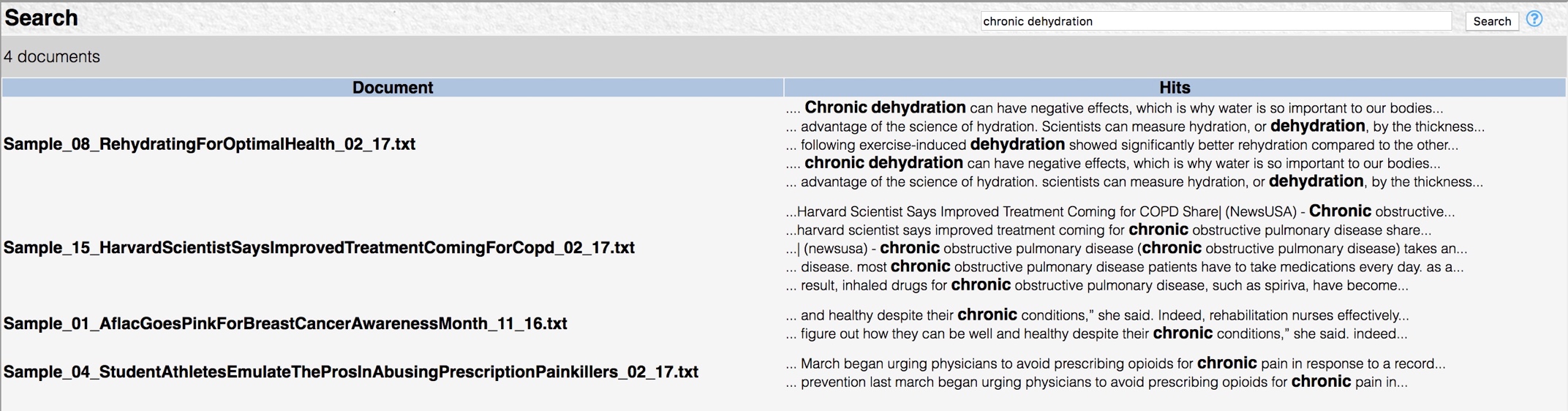
Explore in documents
Select Explore in documents from the pop-up menu to generate a list of all the documents that contain the extraction result. The contents of the Text tab change to display the first document in the list, with the first matching result selected.
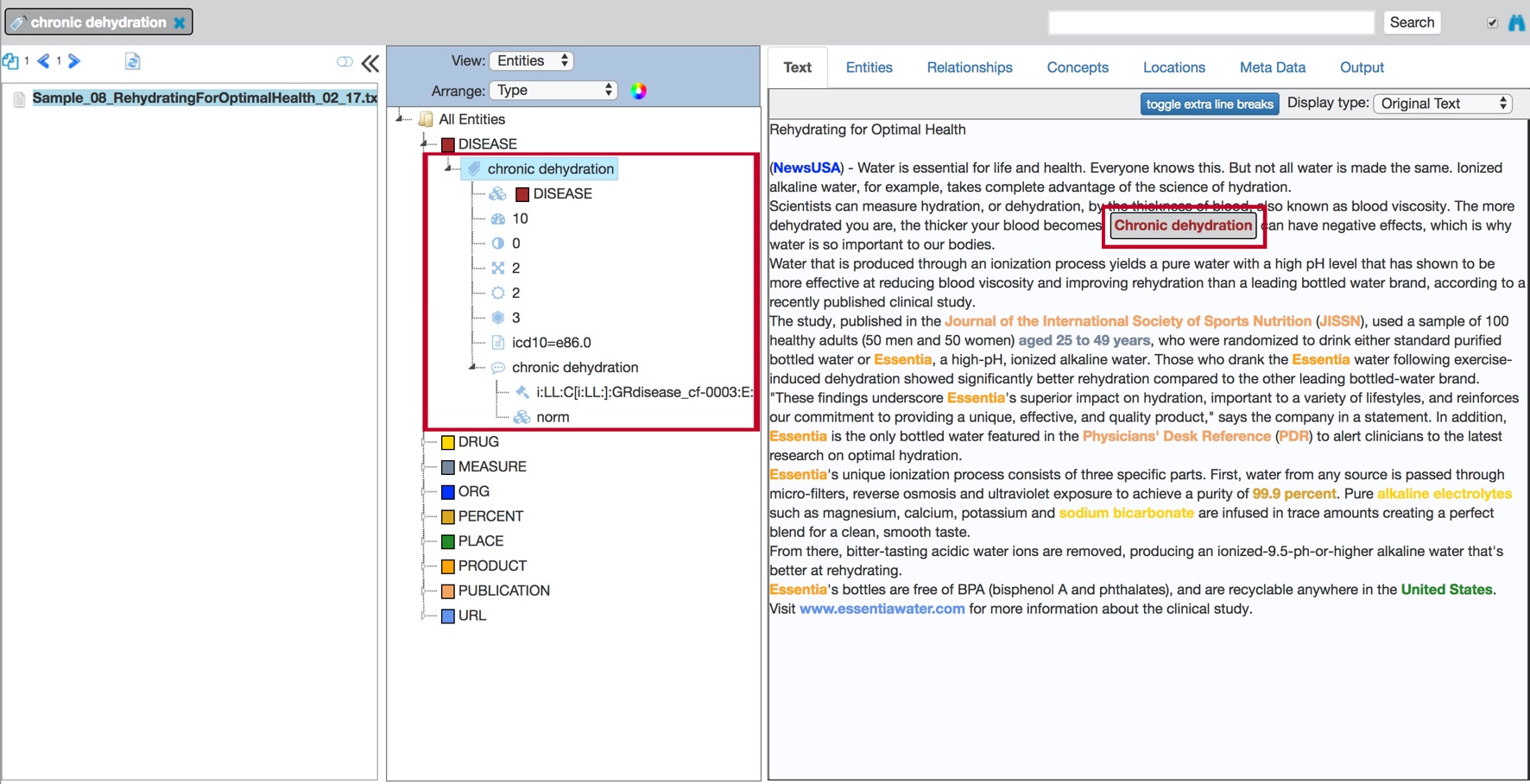
Explore connections
Select Explore connections from the pop-up menu to switch to the Relationships page, which contains information about the relationships in which the selected entity is involved.
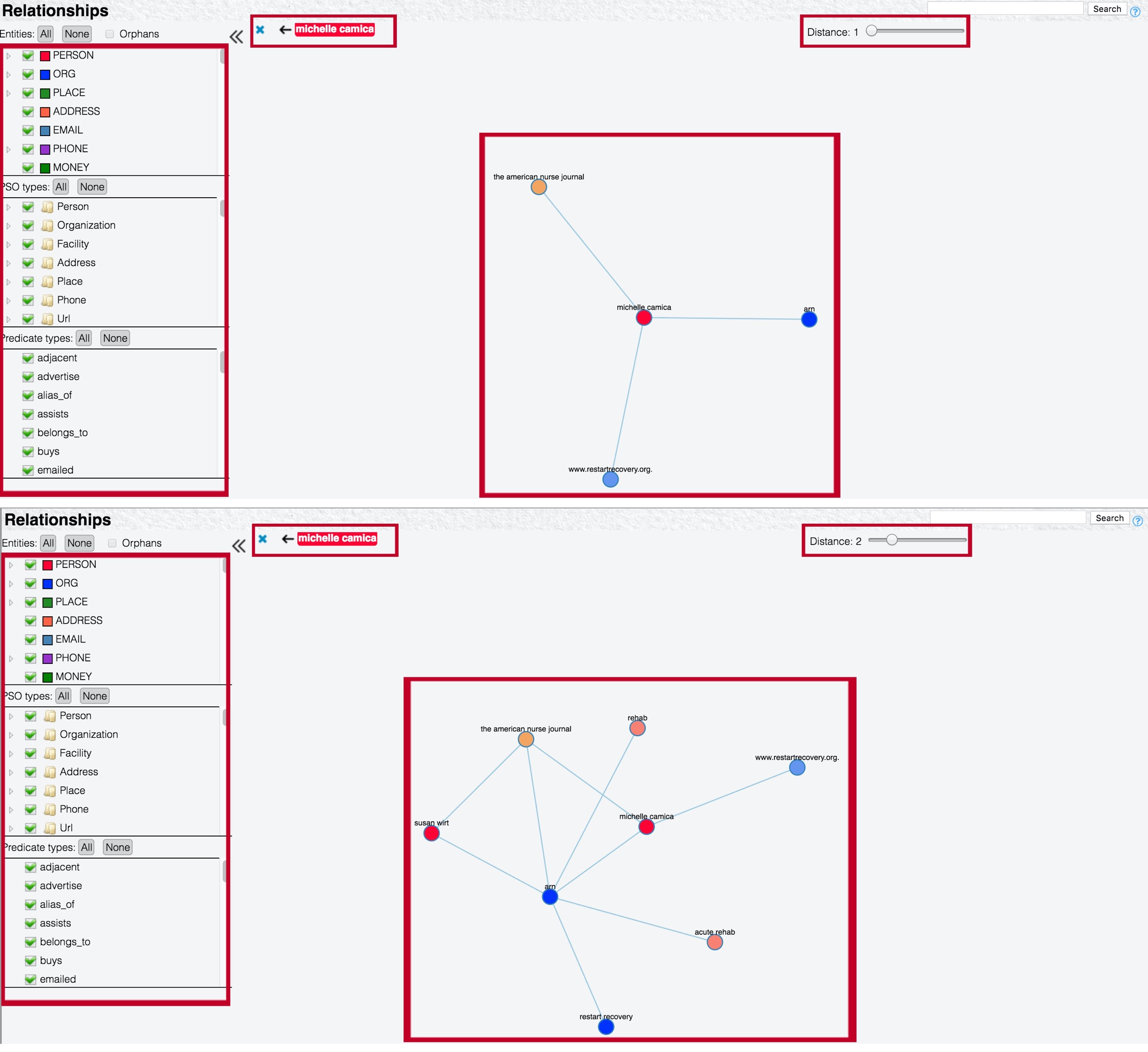
You can adjust the Distance setting to display relationships at up to six degrees of separation from the selected entity.
Look up in lexicon
Select Look up in lexicon from the pop-up menu to display a dialog where you can modify the highlighted term.
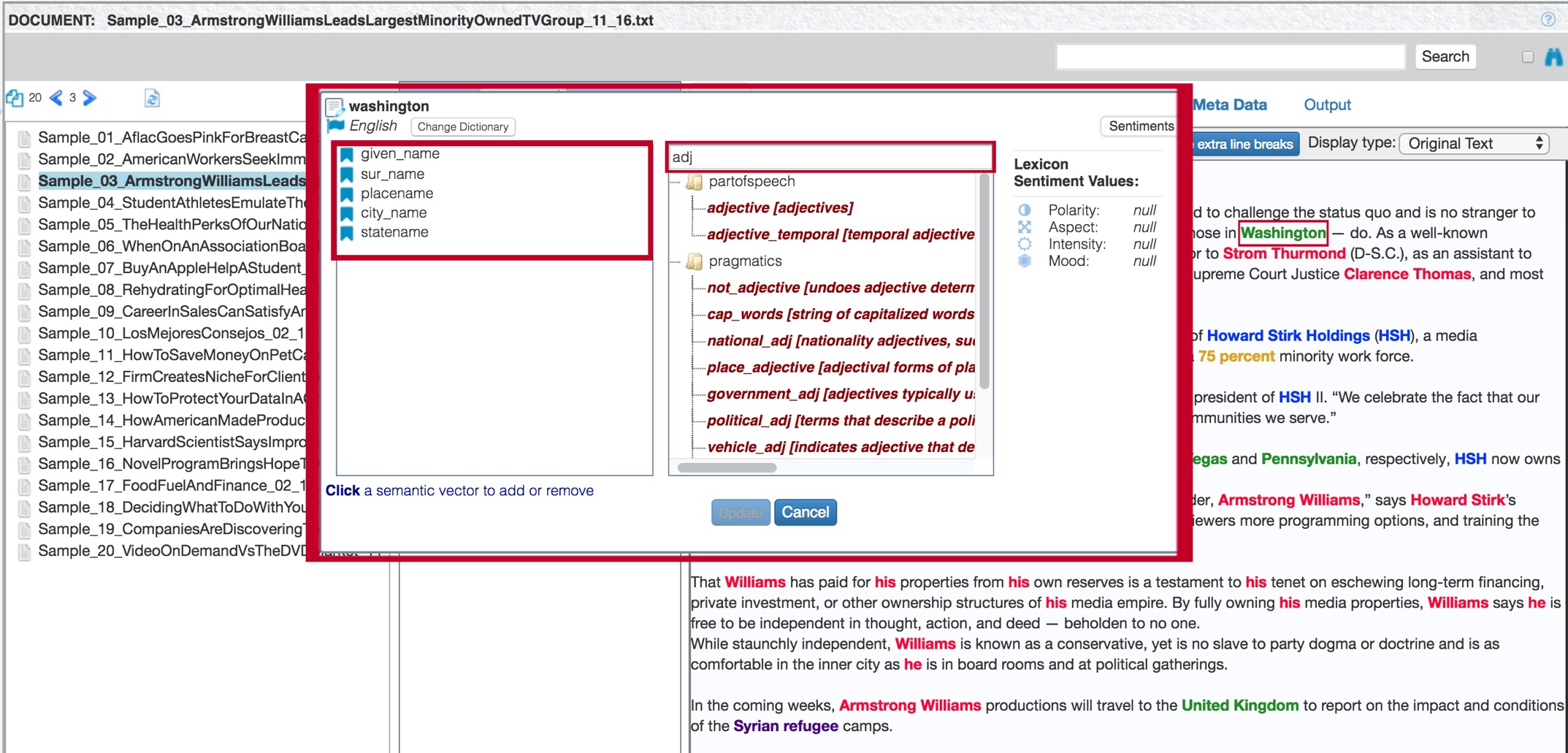
The dialog shows the term, the language of the dictionary that TextChart found it in, and a list of any semantic vectors (SVs) that are associated with it.
To add a new semantic vector to the term, click Add SV and then use the box on the right to find the semantic vector that you want to add. Alternatively, click an existing semantic vector to remove it from the term.
When your changes are complete, click Update to make the TextChart engine recognize them, and then reprocess either the individual document or the entire corpus.
Show rule match detail
Select Show rule match detail from the pop-up menu to display a dialog that contains the steps the TextChart engine took in order to extract (or not extract) a particular result. For example, to extract the PERSON entity "Michelle Camica", the engine took five steps:
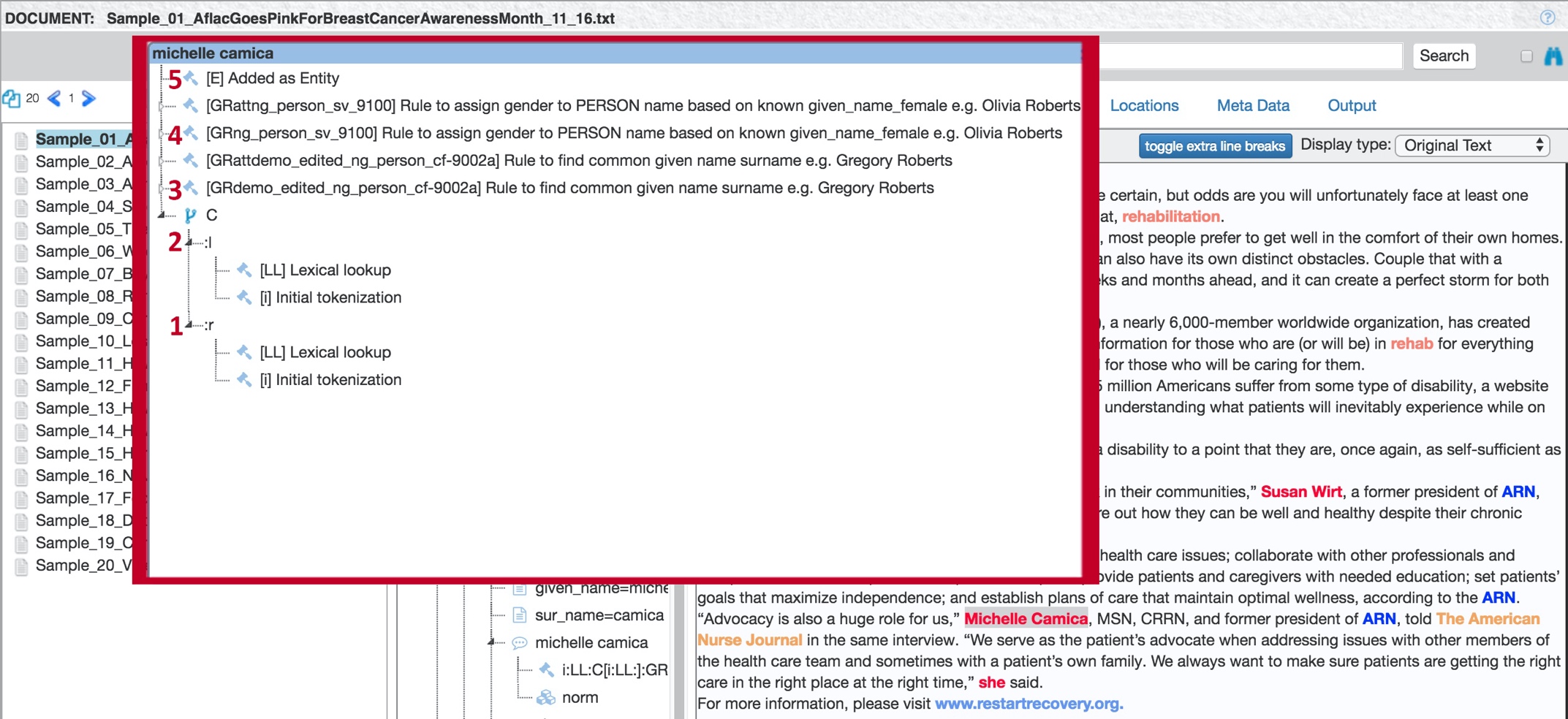
The TextChart engine tokenized the term "Michelle" and looked it up in the dictionaries.
The TextChart engine tokenized the term "Camica" and looked it up in the dictionaries.
The engine executed a linguistic rule whose description contains "...to find common given name and surname..."
The engine executed a second linguistic rule whose description contains "...to assign gender to PERSON name based on known given name female..."
The engine assigned the two tokens "Michelle" and "Camica" to one PERSON entity, based on the linguistic rules that it executed.
To modify a rule, you can double-click it in the list to open the rule editor.