
Matching links in importing
A check for a matching link uses information about the link and the two link end entities. You can check all these records to avoid any duplicates or check none, with results similar to checking an entity. You can also make a partial check, on the end entities only, allowing potential duplicate links but not duplicate entities.
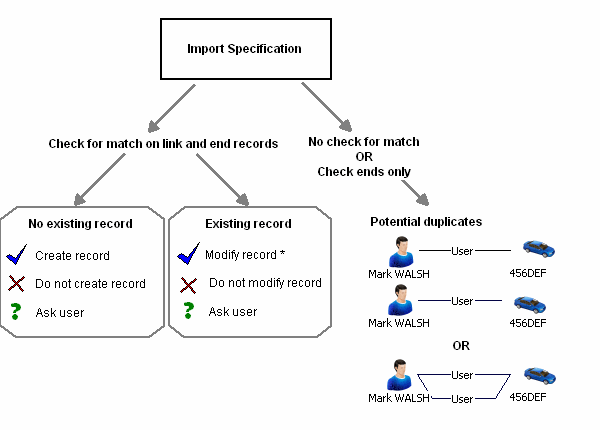
Identifying a matching link
- The link type must be the same.
- Any identifiers on the link must have identical values, as for entities.
- Both end entities must have matching records (in the database).
- The direction of the link must be the same.
- The strength of the link must be the same.
- Always update the existing link record.Note: To avoid overwriting data with empty fields from the source data, you can turn on Do not update existing field values with blank values when setting up the import specification.
- Always leave the record unchanged, that is, ignore the data source.
- Ask the user which option to use, at the time of importing each record.
- Always create a new link record, which is known not to be a duplicate.
- Never create a new record, that is, ignore the data source.
- Ask the user which option to use, at the time of importing each record.
- Create the link only if the end entities exist in the database.
You can choose to allow duplicate links in the same way as you can for entities, by turning off the check for identifiers. If you turn off the check for the link, you can choose separately whether to check the identifiers of the end entities. With links, often you require duplicates, for example it might be important to record each instance of an identical relationship link separately.
After any import of this type, detect and handle any duplicate records.