
Matching entities in importing
When you are importing entities, allow for the possibility that there might be a matching record already in the database. Similarly, the data source itself might contain repeated records. You can detect and handle these situations to suit different data and working practices.
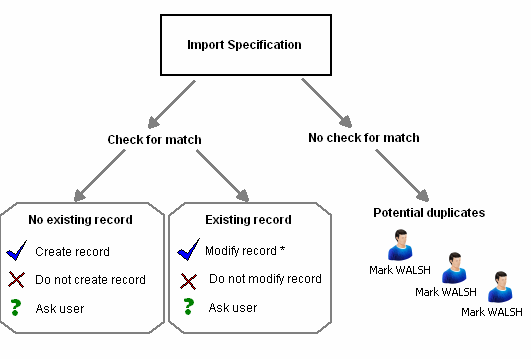
Matching entities have identical values in the identifier fields of the data source and an entity record already in the database.
Identifiers are suggested for each import specification, as either a combination of fields or a single field that is unique. The suggestion is based on the discriminator fields, which you can see in the database design report; you can choose different identifiers if appropriate. All identifier fields must match for there to be a matching record and you must be importing a field to use it as an identifier.
Handling a matching entity
Once a matching entity has been identified, the options for using the information in the data source are:
- Always update the existing entity record - You will usually want to do this if you know that the
import data is reliable and up-to-date.Note: If you want to change the value of a field, that field must not be an identifier when you make the import. To avoid overwriting existing data with empty/blank fields from the source data, you can turn on Do not update existing field values with blank values when setting up the import specification.
- Always leave the record unchanged, that is, ignore the data source - You may want to do this if you think that the import data is older, less complete, or less reliable than information already in the database record.
- At the time of importing each record, ask the user which option to use
Handling a non-matching entity
If an existing entity has not been found, you have a different set of options for using the information in the data source:
- Always create a new entity record, known not to be a duplicate - Do this if you know that the import data is reliable and up to date.
- Never create a new record, that is, ignore the data source - Do this if you think that the import data is old, unreliable, or incomplete; or if working practices restrict how to create a new entity record.
- At the time of importing each record, ask the user which option to use
Creating a potential duplicate entity
In some situations, you may not be able to specify the best option beforehand or decide the best action at the time of importing data. If this is the case, you can choose not to check identifiers, which means that all records in the data source are used to create new records and may therefore produce matching or duplicate records. The import process will not inform you if there are duplicates, so you should make the detection and handling of duplicates part of your work practices following such data import.
For example, you can check for duplicates using iBase tools such as the Matching Records or Duplicate Records Checker, then decide to merge any duplicate records or create links between the duplicates.